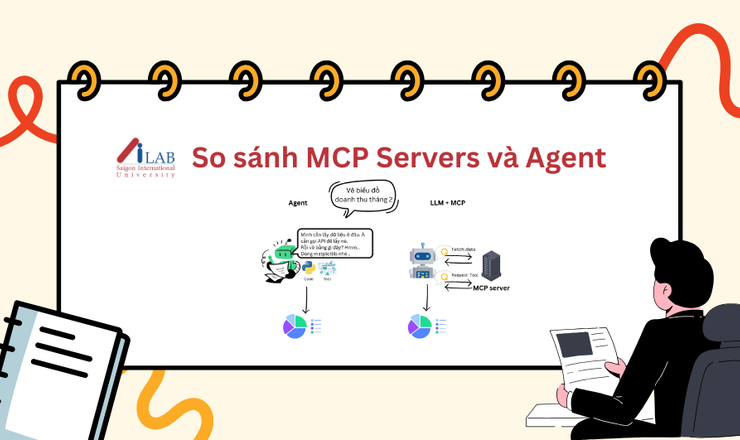
Trong hệ sinh thái AI hiện đại, các mô hình ngôn ngữ lớn (LLM) như GPT-4, Claude 3, Gemini, Mistral hay LLaMA không còn được triển khai theo kiểu đơn lẻ. Thay vào đó, các tổ chức thường kết hợp nhiều mô hình khác nhau để đạt được sự cân bằng giữa hiệu quả, chi phí và độ tin cậy. Tuy nhiên, việc tích hợp này không hề đơn giản: mỗi mô hình có API riêng, yêu cầu bảo mật riêng và cách tính chi phí khác nhau. Điều đó dẫn đến những khó khăn trong quản lý, mở rộng và thay đổi mô hình linh hoạt.

Trong bài trước, chúng ta đã tìm hiểu về Semantic Chunking – kỹ thuật cắt văn bản “có hiểu biết” dựa trên embedding, giúp mô hình AI phân đoạn văn bản thành các phần nhỏ có ý nghĩa để truy xuất hiệu quả. Tuy nhiên, Semantic Chunking vẫn còn một số giới hạn khi phải xử lý các văn bản phức tạp, nơi việc hiểu sâu sắc ngữ cảnh và nội dung chi tiết của từng câu là rất quan trọng.