Trong hệ sinh thái AI hiện đại, các mô hình ngôn ngữ lớn (LLM) như GPT-4, Claude 3, Gemini, Mistral hay LLaMA không còn được triển khai theo kiểu đơn lẻ. Thay vào đó, các tổ chức thường kết hợp nhiều mô hình khác nhau để đạt được sự cân bằng giữa hiệu quả, chi phí và độ tin cậy. Tuy nhiên, việc tích hợp này không hề đơn giản: mỗi mô hình có API riêng, yêu cầu bảo mật riêng và cách tính chi phí khác nhau. Điều đó dẫn đến những khó khăn trong quản lý, mở rộng và thay đổi mô hình linh hoạt.
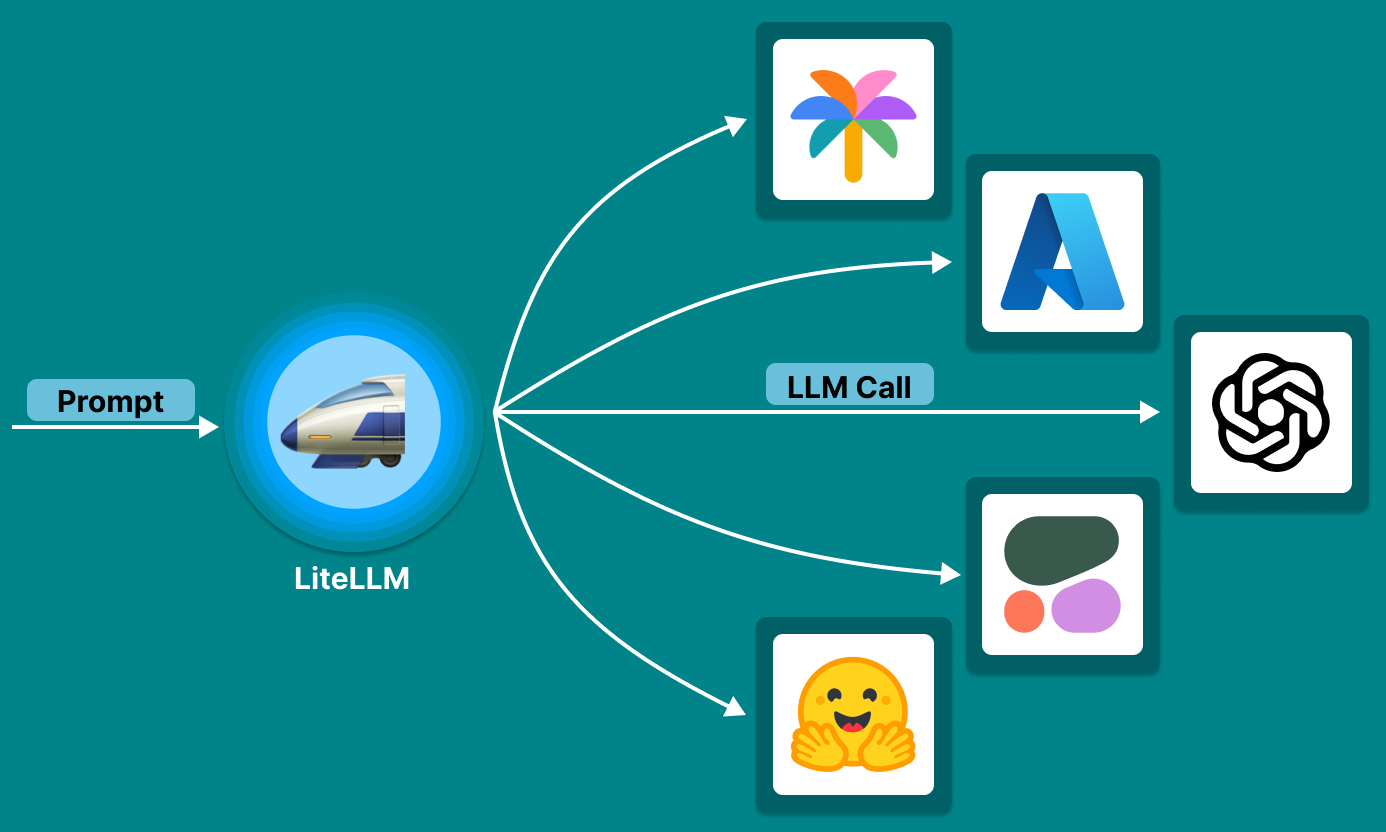
LiteLLM được xây dựng để giải quyết trực tiếp vấn đề này. Nó đóng vai trò như một LLM Gateway – tầng trung gian giúp chuẩn hóa việc gọi LLM, điều phối truy vấn thông minh và kiểm soát chi phí trong môi trường đa mô hình.
LiteLLM là gì?
LiteLLM là một thư viện Python mã nguồn mở cho phép lập trình viên gọi đến nhiều mô hình ngôn ngữ khác nhau như OpenAI, Anthropic, Google, Cohere, Mistral, HuggingFace… thông qua một API thống nhất, tương thích hoàn toàn với chuẩn openai.ChatCompletion.create.
Nhờ đó, nhà phát triển có thể viết code một lần duy nhất và dễ dàng hoán đổi giữa các mô hình mà không cần viết lại toàn bộ logic ứng dụng.

LiteLLM Proxy – Thành phần LLM Gateway
Mặc dù LiteLLM có thể được dùng trực tiếp trong các ứng dụng Python, thì LiteLLM Proxy mới là thành phần then chốt biến LiteLLM trở thành một LLM Gateway hoàn chỉnh.
- Là một REST API server tương thích hoàn toàn với OpenAI API. LiteLLM cung cấp API chuẩn OpenAI, bao gồm các endpoint phổ biến như:
Nhờ đó, bất kỳ ứng dụng nào hiện đang dùng OpenAI đều có thể chuyển sang dùng Claude, Gemini, Mistral hoặc mô hình cục bộ mà không cần chỉnh sửa code.
- /v1/chat/completions
- /v1/completions
- /v1/embeddings
- /v1/chat/completions
- Cho phép các ứng dụng frontend, chatbot, backend (bất kể viết bằng ngôn ngữ gì) gọi đến bất kỳ LLM nào chỉ thông qua một endpoint duy nhất.
- Hỗ trợ cấu hình nâng cao: routing, load balancing, fallback, caching, logging, quota và nhiều tính năng khác.
- Load balancing: LiteLLM hỗ trợ triển khai nhiều backend cho cùng một mô hình, với trọng số tùy chỉnh. Điều này giúp chia tải giữa nhiều API key, vùng địa lý hoặc tài khoản khác nhau.
- Routing: LiteLLM cung cấp nhiều cơ chế điều phối thông minh giúp tăng độ tin cậy hệ thống:
- Cooldowns: tự động "hạ tải" backend gặp lỗi liên tục.
- Retries: thử lại backend khác khi có lỗi (timeout, quota exceeded…).
- Custom retry by error type: cấu hình hành vi retry riêng biệt cho từng loại lỗi.
- Caching: LiteLLM hỗ trợ caching response cho các truy vấn giống nhau. Cache có thể được lưu bằng bộ nhớ hoặc Redis.
- Giảm số lần gọi LLM thật → tiết kiệm chi phí.
- Giảm độ trễ phản hồi.
- Phù hợp cho hệ thống RAG, dashboard, chatbot nhiều người dùng.
- logging & quota: LiteLLM có thể ước tính chi phí sử dụng theo số token tiêu thụ và giá từng mô hình. Đồng thời:
- Giới hạn số lần gọi / token theo API key.
- Ghi log chi tiết theo người dùng, model, thời điểm.
- Kết nối với hệ thống theo dõi như Prometheus, Datadog, Kafka.
- Hệ thống hỗ trợ nhiều cấp độ debug:
- Basic Debugging: log theo request .
- Detailed Debugging: log kèm prompt, completion.
- Very Detailed Debugging: log full metadata, thời gian xử lý, chi phí ước tính.
- Tương thích rộng & mở rộng dễ dàng: LiteLLM hỗ trợ hơn 100 mô hình đến từ các nền tảng lớn như OpenAI, Gemini, Claude,...
- Người dùng nâng cao có thể viết thêm custom provider hoặc callback để tích hợp hệ thống riêng.
LiteLLM Proxy giúp bạn triển khai một cổng API duy nhất (giống OpenAI), nhưng thực chất phía sau có thể là nhiều mô hình ngôn ngữ khác nhau – từ cloud đến local. LiteLLM Proxy không chỉ đơn thuần là một adapter API – nó là một LLM Gateway nhẹ nhưng mạnh, phù hợp để triển khai trong mọi hệ thống AI hiện đại. Với khả năng:
- Chuẩn hóa API LLM.
- Điều phối thông minh giữa nhiều backend.
- Theo dõi và giới hạn chi phí.
- Hỗ trợ caching, retry, fallback.
- Mở rộng linh hoạt cho nhiều loại mô hình.
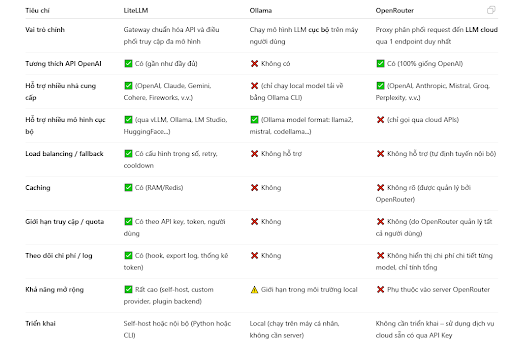
Bảng sau đây giúp chúng ta phân biệt LiteLLM, Ollama hay OpenRouter nhằm khai thác hiệu quả cả 3 công cụ này: