Hypothetical Document Embeddings là gì?
Hypothetical Document Embeddings (HyDE) là một phương pháp kết hợp giữa các mô hình ngôn ngữ lớn (LLM) và không gian biểu diễn dữ liệu (embedding). Thay vì chỉ dựa vào dữ liệu hiện có, HyDE tận dụng khả năng của LLM để tạo ra các tài liệu giả định (hypothetical documents). Các tài liệu này được thiết kế để tăng cường dữ liệu và cải thiện khả năng truy xuất thông tin.
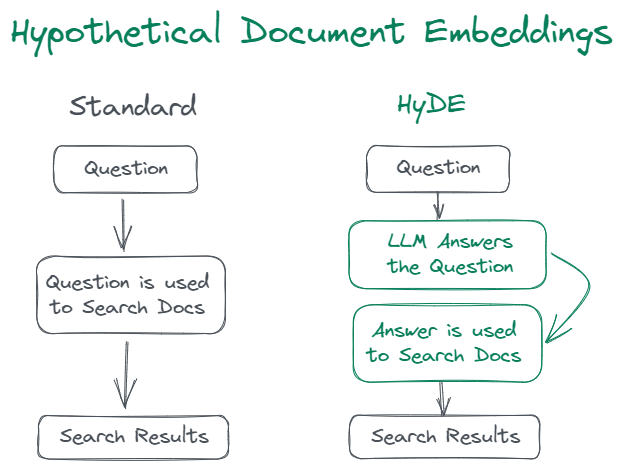
Hình 1. Sự khác biệt giữa mô hình truy vấn bình thường và mô hình có sử dụng HyDE. Nguồn ảnh: https://medium.aiplanet.com/advanced-rag-improving-retrieval-using-hypothetical-document-embeddings-hyde-1421a8ec075a
Những Đặc Điểm Nổi Bật Của HyDE
- Hiểu bối cảnh: HyDE không chỉ xử lý truy vấn một cách bề mặt mà còn dựa vào bối cảnh để tạo ra các tài liệu giả định liên quan nhất.
-
Tối ưu hóa dữ liệu: Thay vì yêu cầu một lượng lớn dữ liệu huấn luyện, HyDE tạo ra dữ liệu giả định để giảm tải lưu trữ và tăng cường hiệu quả sử dụng.
-
Khả năng thích ứng cao: Với các truy vấn phức tạp hoặc không rõ ràng, HyDE có thể bổ sung ngữ cảnh để đạt kết quả chính xác và chi tiết hơn.
Cách Hoạt Động Của HyDE
Hình minh họa 2 dưới đây giải thích rõ các bước hoạt động của HyDE:
-
Nhận Truy Vấn Người Dùng: Người dùng đặt câu hỏi hoặc truy vấn dưới nhiều dạng khác nhau, ví dụ:
-
"Mất bao lâu để nhổ răng khôn?"
-
"Đại dịch COVID-19 đã ảnh hưởng như thế nào đến sức khỏe tinh thần?"
-
"Con người bắt đầu sử dụng lửa từ khi nào?" (truy vấn bằng tiếng Hàn).
-
Tạo Tài Liệu Giả Định: Khi nhận truy vấn, HyDE sử dụng mô hình LLM để sinh ra một tài liệu giả định liên quan đến truy vấn. Các tài liệu này phản ánh nội dung hoặc ngữ cảnh mà truy vấn nhắm đến. Trong ví dụ, HyDE sử dụng mô hình GPT để tạo ra các đoạn văn hoặc tài liệu giả định nhằm trả lời câu hỏi một cách cụ thể và chi tiết. Các đoạn văn này mang tính chất giải thích và liên quan trực tiếp đến truy vấn.
-
Ví dụ, cho câu hỏi "Mất bao lâu để nhổ răng khôn?", hệ thống tạo ra đoạn văn: "Thông thường mất khoảng 30 phút đến 2 giờ để nhổ một chiếc răng khôn...".
-
Đối với câu hỏi khoa học, hệ thống tạo ra tài liệu phù hợp với ngữ cảnh nghiên cứu, ví dụ: "Trầm cảm và lo âu đã tăng 20% kể từ khi bắt đầu đại dịch...".
-
Chuyển Đổi Sang Embedding: Sau khi tạo, tài liệu giả định được chuyển đổi thành vector embedding bằng cách sử dụng các mô hình embedding hiện đại. Điều này giúp mã hóa nội dung thành định dạng dễ dàng xử lý trong không gian số.
-
So Khớp Và Truy Xuất: Embedding của tài liệu giả định sẽ được so khớp với các embedding trong cơ sở dữ liệu để tìm ra những kết quả phù hợp nhất. Phương pháp này không chỉ tăng độ chính xác mà còn mở rộng phạm vi truy vấn.
-
Đối với câu hỏi "Mất bao lâu để nhổ răng khôn?", tài liệu thực tế sẽ là "Quá trình nhổ răng khôn có thể kéo dài từ vài phút đến hơn 20 phút tùy vào từng trường hợp...".
-
Đối với câu hỏi "Con người sử dụng lửa từ khi nào?" bằng tiếng Hàn, hệ thống sẽ tìm các nghiên cứu lịch sử liên quan đến việc Homo erectus sử dụng lửa khoảng 1.42 triệu năm trước.
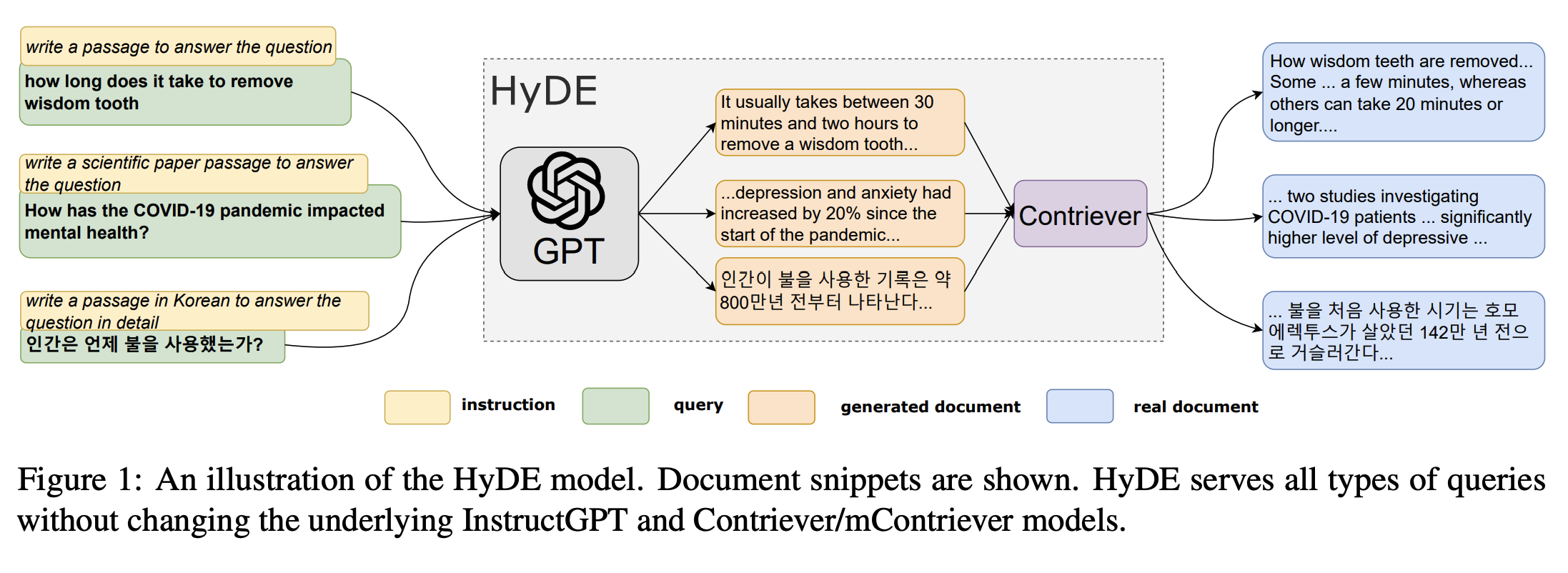 Hình 2. Mô tả luồng hoạt động của HyDE. Nguồn ảnh: Original Paper, Gao et al, https://aclanthology.org/2023.acl-long.99/
Hình 2. Mô tả luồng hoạt động của HyDE. Nguồn ảnh: Original Paper, Gao et al, https://aclanthology.org/2023.acl-long.99/
Mặc dù có nhiều ưu điểm, HyDE cũng đối mặt với các thách thức như đảm bảo chất lượng của tài liệu giả định và tối ưu hóa hiệu suất trong các trường hợp sử dụng cụ thể. Tuy nhiên, với tiềm năng ứng dụng rộng rãi, HyDE đang mở ra cánh cửa mới cho các giải pháp NLP sáng tạo, hiệu quả và toàn diện hơn.