
Parent-Child Retriever là một phương pháp tiên tiến trong hệ thống Retrieval-Augmented Generation (RAG), còn được biết đến với tên Parent-Document-Retriever. Khác với các phương pháp cơ bản như Basic Retriever, Parent-Child Retriever không chỉ tập trung vào việc tìm kiếm những đoạn văn bản có nội dung tương đồng, mà còn mở rộng ngữ cảnh để cung cấp thêm thông tin bao quanh, giúp tạo ra các câu trả lời chính xác và toàn diện hơn.
Parent-Child Retriever Là Gì?
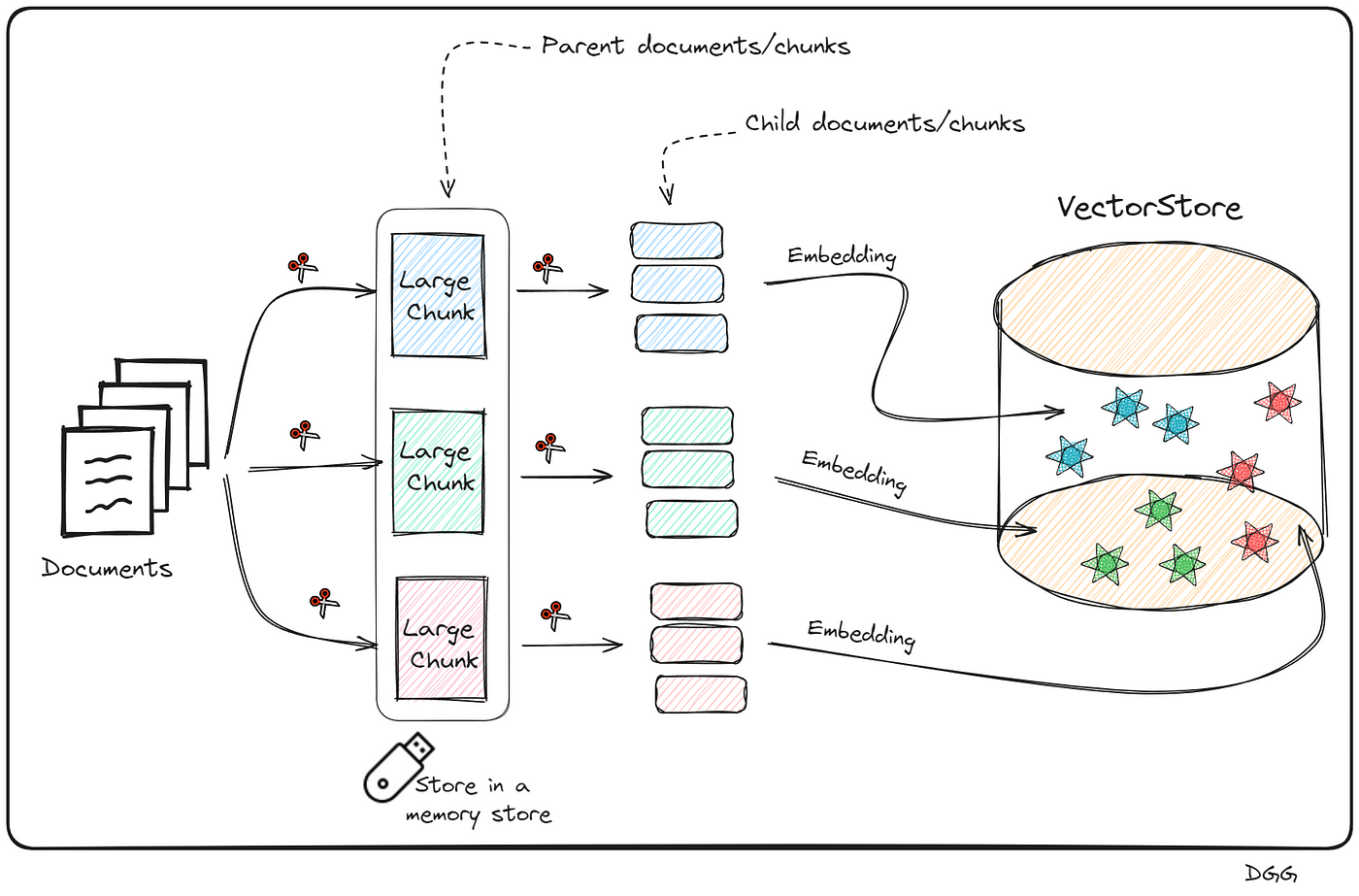
Trong Parent-Child Retriever, nội dung văn bản được chia thành các đoạn lớn hơn gọi là parent chunks và tiếp tục được chia nhỏ thành các đoạn con gọi là child chunks. Mỗi child chunk sẽ được chuyển đổi thành embedding, giúp hệ thống hiểu được ý nghĩa ngữ nghĩa của đoạn văn. Trong quá trình tìm kiếm, các child chunk này sẽ được so sánh với câu hỏi của người dùng để tìm ra những đoạn có ý nghĩa tương đồng nhất. Các parent chunk tương ứng của child chunk sẽ được sử dụng để cung cấp ngữ cảnh rộng hơn cho câu trả lời.
Nguồn ảnh: Advanced Retriever Techniques to Improve Your RAGs (https://towardsdatascience.com/advanced-retriever-techniques-to-improve-your-rags-1fac2b86dd61)
Các Bước Triển Khai Parent-Child Retriever
- Chia tài liệu thành các parent chunk: Tài liệu được chia thành các đoạn lớn hơn để làm đơn vị cha.
- Chia tiếp các parent chunk thành child chunk: Mỗi parent chunk tiếp tục được chia nhỏ thành các child chunk để chuẩn bị cho việc tạo embedding.
- Tạo embedding cho từng child chunk: Sử dụng một mô hình embedding để chuyển các child chunk thành vector biểu diễn ngữ nghĩa.
- Tìm kiếm độ tương đồng vector: Embedding của câu hỏi người dùng sẽ được so sánh với các embedding của child chunk. Các child chunk có độ tương đồng cao nhất được chọn.
- Truy xuất parent chunk: Sau khi chọn các child chunk phù hợp, hệ thống sẽ lấy thêm các parent chunk tương ứng để bổ sung ngữ cảnh.
Ưu Điểm và Ứng Dụng của Parent-Child Retriever
Ưu Điểm
Parent-Child Retriever vượt trội hơn so với Basic Retriever nhờ khả năng lấy thêm ngữ cảnh xung quanh, đặc biệt hữu ích trong các trường hợp:
- Khi tài liệu chứa nhiều chủ đề, dễ gây nhiễu cho embedding: Các child chunk nhỏ hơn giúp giảm thiểu nhiễu, trong khi parent chunk bổ sung ngữ cảnh rộng hơn.
- Cải thiện chất lượng câu trả lời: Các thông tin ngữ cảnh giúp tăng độ chính xác của câu trả lời.
- Dễ triển khai với hiệu quả cao: Với một chút bổ sung về cấu hình, người dùng có thể cải thiện đáng kể hiệu quả của hệ thống truy xuất.
Ứng Dụng Thực Tế
Parent-Child Retriever phù hợp với các hệ thống truy vấn mà câu hỏi cần ngữ cảnh mở rộng. Các ứng dụng điển hình có thể bao gồm:
- Hệ thống hỏi đáp nâng cao: Tạo ra các câu trả lời toàn diện hơn với ngữ cảnh đầy đủ.
- Phân tích tài liệu phức tạp: Tìm kiếm thông tin cụ thể trong các tài liệu đa chủ đề và cung cấp ngữ cảnh liên quan.
- Hệ thống hỗ trợ quyết định: Đưa ra quyết định dựa trên các thông tin cụ thể cùng ngữ cảnh rộng hơn, giúp giảm thiểu sai sót.
Hiện thực hóa một Parent-Child Retriever (coming soon).
1. Load các thư viện cần thiết (langchain):
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter2. Đọc tệp văn bản:
loaders = [
TextLoader("paul_graham_essay.txt"),
TextLoader("state_of_the_union.txt"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
3. Tạo child splitter (chia nhỏ các tài liệu ra thành các chunk):
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)4. Tạo một vector database sử dụng Chroma, chế độ lưu trữ trong bộ nhớ InMemoryStore:
# The vectorstore to use to index the child chunks
vectorstore = Chroma(
collection_name="full_documents",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
5. Tìm kiếm theo chunk nhỏ
sub_docs = vectorstore.similarity_search("justice breyer")
print(sub_docs[0].page_content)
6. Tìm kiếm trả về cả tài liệu lớn
retieved_docs = retriever.invoke("justice breyer")
len(retrieved_docs[0].page_content)
Xem thêm tại đây: https://python.langchain.com/docs/how_to/parent_document_retriever/
