Hôm nay mình sẽ giới thiệu về khái niệm về Knowledge Distillation (Chắt lọc Tri thức) trong machine learning.
1. Giới thiệu
Knowledge Distillation là một trong những phương pháp Transfer Learning, nhằm chuyển đổi và truyền dạy kiến thức từ một mô hình lớn, phức tạp sang một mô hình nhỏ và đơn giản hơn. Ý tưởng của Knowledge Distillation là sử dụng thông tin được học từ mô hình lớn (Teacher model) để huấn luyện một mô hình nhỏ hơn (Student model). Quá trình này giúp cải thiện hiệu suất của mô hình con, đồng thời giảm bớt độ phức tạp tính toán và tài nguyên yêu cầu.
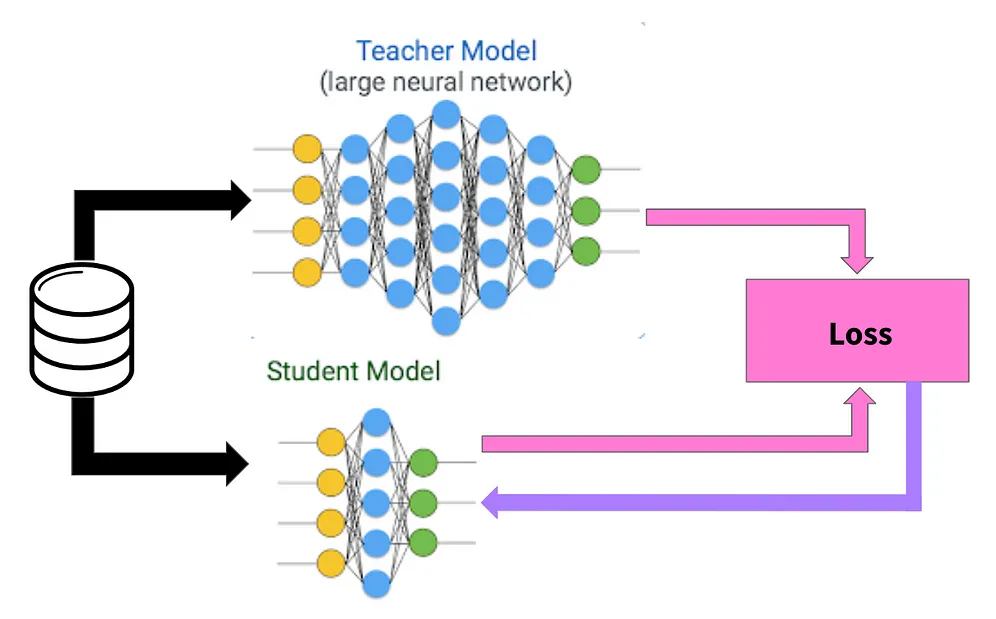
2. Huấn luyện Distillation Knowledge
Để huấn luyện Distillation Knowledge, đầu tiên là lựa chọn và huấn luyện mô hình Teacher. Sau khi mô hình Teacher đạt đến độ chính xác mong muốn, chúng ta sẽ sử dụng Teacherđể huấn luyện cho mô hình Student.
Huấn luyện mô hình Student nhằm mục đích mô phỏng lại việc mô hình Teacher xử lý thông tin từ dữ liệu đầu vào. Do đó lúc này dữ liệu sẽ được đưa vào cùng lúc với mô hình Teacher và Student , điểm khác biệt mô hình Teacher sẽ được đặt ở trạng thái suy luận (tức không cập nhật tham số) và mô hình Student sẽ được đặt ở trạng thái huấn luyện. Đồng thời thay vì sử dụng nhãn là ground-truth như với các mô hình phân loại thông thường, chúng ta sẽ sử dụng output của mô hình Teacher để làm nhãn cho mô hình Student .
Lúc này hàm loss của mô hình có dạng:
Ldl(xi;W) = H(qit,qis)
Với xi là quan sát tại i, qit và qis là phân phối xác xuất dự báo của Teacher va Student.
Ngoài ra, nhằm làm cho phân phối xác suất ở hàm softmax trở nên mượt mà hơn, người ta thường bổ sung thêm siêu tham số T trong hàm softmax của mô hình Student :
Đồng thời, thông qua thực nghiệm người ta nhận thấy rằng việc bổ sung thông tin cho hàm loss từ ground-truth, thay vì chỉ học từ việc dự đoán của mô hình Teacher làm cho mô hình Student có khả năng học tốt hơn.
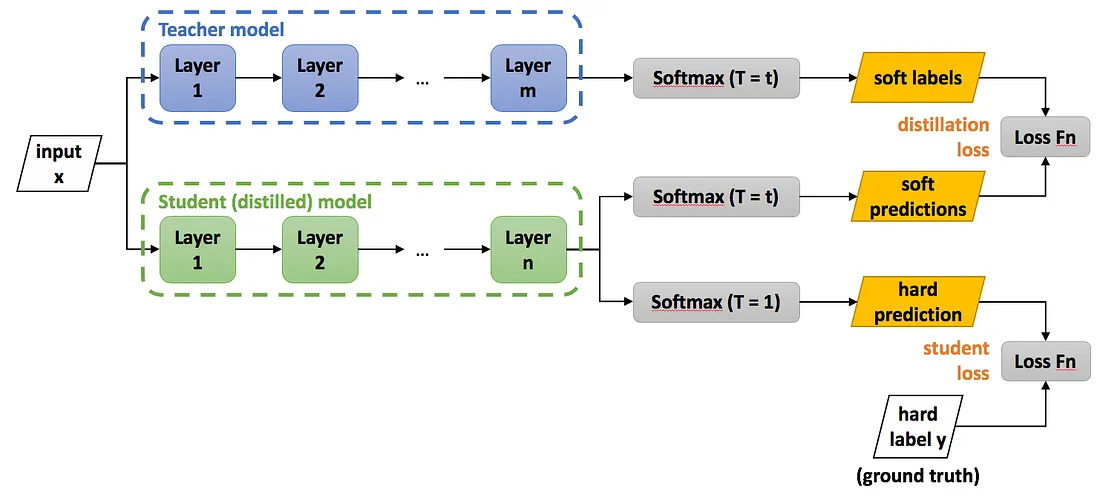
Hàm loss lúc này sẽ có dạng:
Lfinal(xi;W) = a*Ldl(xi;W) + b*Ldl(xi;W)
Với a,b là các siêu tham số.
3. Thực nghiệm:
Các bạn có thể tham khảo 1 hướng dẫn về Knowledge Distillation của Alexandros Chariton trên nền tảng google Colab (link)
Ở thực nghiệm này tác giả huấn luyện 1 mô hình teacher với tập dữ liệu CIFAR10. Tiếp đó là huấn luyện với mô hình Student mà không sử dụng Knowledge Distillation, sau đó là áp dụng Knowledge Distillation với một số tinh chỉnh khác.
Kết quả huấn luyện được thể hiện như sau:
Teacher accuracy: 75.69%
Student accuracy without Teacher: 69.99%
Student accuracy with CE + KL: 71.09%
Student accuracy with CE + CosineLoss: 70.17%
Student accuracy with CE + RegressorMSE: 71.16%
4. Tổng kết
Thông qua bài viết, ta có thể thấy rằng Knowledge Distilation là phương pháp học thú vị dựa trên việc học thực tế của con người. Đồng thời, cho thấy việc áp dụng Knowledge Distillation cho phép sử dụng một mô hình nhỏ hơn, tuy nhiên vẫn đạt được những kết quả khả quan nhờ được kế thừa những tri thức từ những mô hình lớn.
5. Tham khảo
- Knowledge Distillation : Simplified | by Prakhar Ganesh | Towards Data Science
- Knowledge Distillation. Knowledge distillation is model… | by Ujjwal Upadhyay | Neural Machine | Medium
- https://colab.research.google.com/github/pytorch/tutorials/blob/gh-pages/_downloads/a19d8941b0ebb13c102e41c7e24bc5fb/knowledge_distillation_tutorial.ipynb